



В начале 2025-го мы задались простым вопросом: что будет, если клиент ищет подрядчика не в Google, а просто спрашивает у ChatGPT — «кто сделает приложение для доставки»? Кого назовёт модель? Точно не того, у кого больше беклинков. Назовёт того, чей контент она смогла прочитать, понять и процитировать.
Тогда мы решили проверить всё на себе. Взяли собственный блог и несколько клиентских продуктов и начали готовить контент так, чтобы его подхватывал AI. Где-то сработало сразу, где-то пришлось переделывать по несколько раз. Этим опытом и делимся — без теории ради теории.

Дальше расскажем, что мы поняли про разницу между ними, покажем таблицу, с которой можно сразу работать, и разберём пять шагов, которые реально двигают видимость. Со ссылками на исследования там, где они есть, — чтобы это было не «нам так кажется», а проверяемые вещи.
Почему фудтеху уже нельзя игнорировать AI-поиск
Поиск перестал быть единственной дверью, через которую к вам приходят клиенты. Ещё в 2024-м Gartner предсказал, что объём классического поиска упадёт на 25% к 2026 году: запросы, которые раньше начинались в Google, всё чаще уходят к AI-чат-ботам и ассистентам. Видно это и по цифрам — по отчёту Cloudflare за 2025 год, за год AI-боты стали в 15 с лишним раз чаще ходить на страницы, чтобы прямо сейчас ответить на вопрос пользователя; активнее всех — GPTBot, ClaudeBot и PerplexityBot.
На практике это значит вот что. Ресторанная сеть выбирает приложение лояльности, оператор dark kitchen ищет софт для доставки, стартап прикидывает MVP — и почти всегда первый «поиск» это разговор с LLM (большой языковой моделью, той самой, что стоит за ChatGPT, Claude и Perplexity). Если ваши страницы и кейсы не разложены так, чтобы модель вытащила из них суть, вас не будет в ответе ровно тогда, когда человек составляет короткий список. В СНГ к этим движкам добавились Алиса с YandexGPT и GigaChat — фронт только шире. Фудтех тут пока в начале пути, и в этом удача: кто структурирует контент первым, заберёт AI-рекомендации, пока ниша свободна.

5 практических способов повысить прибыль и сократить расходы
Читать статьюЧто такое GEO и как RAG решает, кого процитировать
Под капотом — механизм RAG (Retrieval-Augmented Generation, генерация с поиском по базе). Когда вы спрашиваете Perplexity или Claude с веб-поиском, система на лету достаёт из индекса подходящие куски текста и строит ответ уже на них. И вот тут ключевое: берётся не страница целиком, а отдельный фрагмент. Поэтому старый вопрос «ранжируется ли моя страница?» мы для себя заменили на новый — «сможет ли модель вырезать отсюда один абзац и выдать его как готовый ответ?»
Чтобы абзац можно было так вырезать, мы следим за тремя вещами. Он понятен сам по себе, без текста вокруг. В нём есть конкретика — точные цифры и названия, за которые модель цепляется и которые легко проверить. И над ним стоит заголовок, который прямо говорит, на какой вопрос абзац отвечает. На деле страница про программу лояльности, где сразу есть определение, жёсткая цифра по удержанию и короткий FAQ, попадает в ответы AI заметно чаще, чем лонгрид на 3000 слов, где те же факты размазаны по тексту. Если хочется сперва разобраться, как машины вообще читают сайты, — у нас есть разбор структурированных данных, а про то, живо ли ещё классическое SEO, мы написали отдельно.
SEO vs GEO — в чём для нас оказалась разница
Если совсем коротко: SEO мы делаем ради ранжирования, GEO — ради цитирования. Инструменты местами те же — без хорошего контента и здорового сайта никуда, — но сигналы у каждого свои. Вот как мы разложили это для себя:
| Параметр | SEO (Google, Яндекс) | GEO (ChatGPT, Claude, Perplexity) |
| Цель | Позиция в SERP (странице выдачи) | Цитата внутри AI-ответа |
| Ключевой сигнал | Беклинки + PageRank | Структура контента + конкретные названия |
| Что меряем | Позицию по ключевому слову | Попадание в топ-источники ответа |
| Роль ключевых слов | Критична для ранжирования | Вторична; важнее смысл и контекст |
| Разметка Schema.org | Помогает Google понять тип контента | На цитирование у LLM не влияет |
| FAQ-блоки | Шанс на Featured Snippet | Прямой источник, который LLM цитируют |
| Скорость загрузки | Фактор ранжирования | На цитирование у LLM не влияет |
| Конкретные названия | Вторичный сигнал | Ключевой: задают модели контекст |
Большая часть SEO переезжает в GEO без изменений: качественный контент, настоящий E-E-A-T (опыт, экспертиза, авторитетность, надёжность) и сайт, который нормально открывается и индексируется. Что мы добавляем специально под GEO — это структуру: самодостаточные блоки, понятные определения, конкретные названия, FAQ и файл /llms.txt (про него в конце).
В фудтехе разница особенно видна: страницу, где прямо написано «работаем с iiko, r_keeper, Poster и Quick Resto», цитируют чаще, чем ту, где сказано «интегрируемся с любой кассой». Модель цепляется за названия.


5 шагов, которые мы проходим сами
GEO не требует переписывать весь сайт — мы и не переписываем. Хватает пары структурных правок на важных страницах. Ниже — ровно то, что делаем руками, в том порядке, в каком обычно беремся.
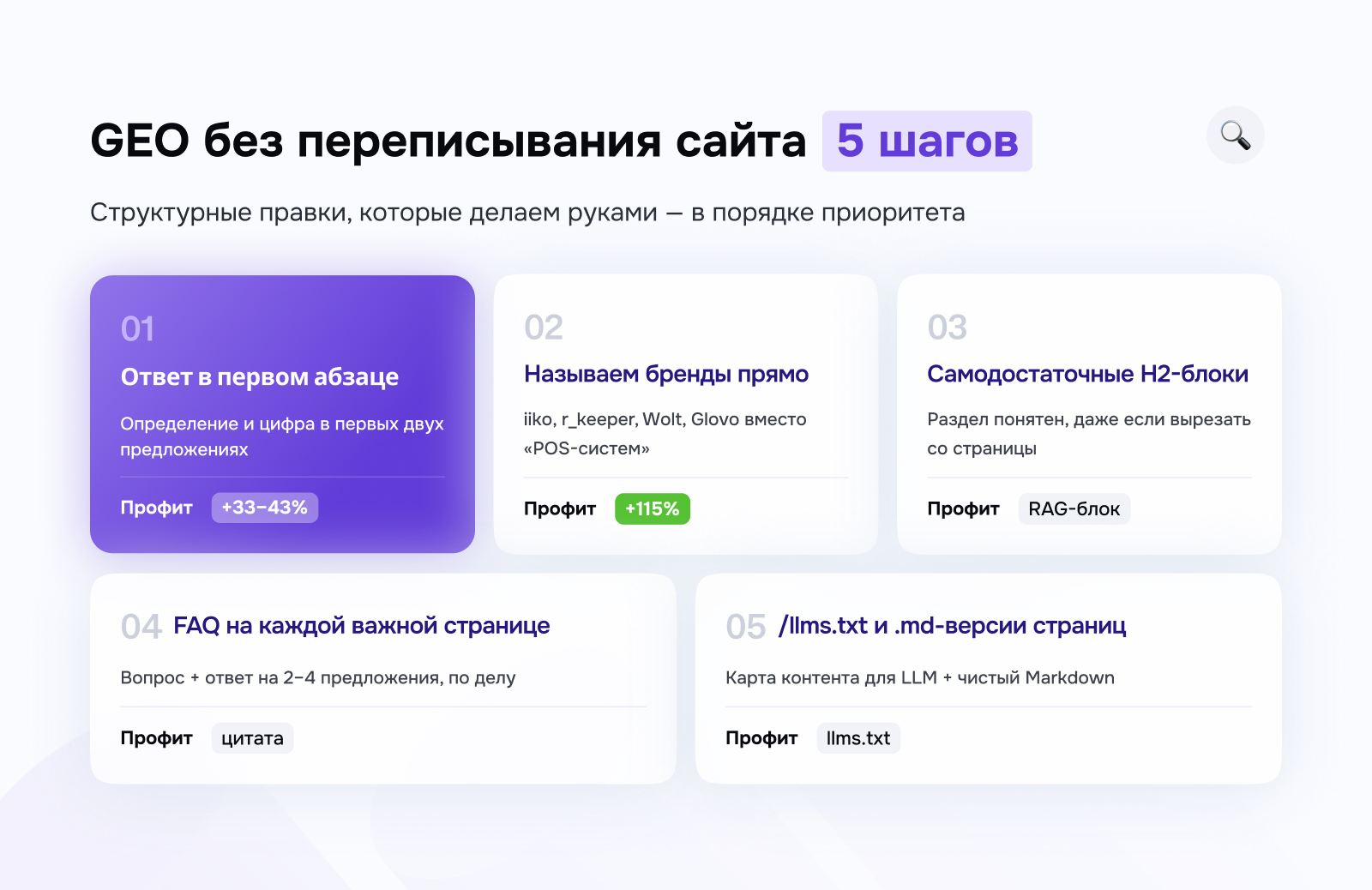
1. Переписываем первый абзац так, чтобы он сразу отвечал на вопрос
Что делаем. Первый абзац важной страницы должен сразу давать ответ на её главный вопрос — без разгона. Модель читает первый смысловой блок как ответ пользователю, поэтому начинаем с определения и цифры.
Как это выглядит. Страницу «Программа лояльности для ресторана» открываем так: «Программа лояльности возвращает гостей за счёт баллов, скидок и персональных предложений. У сетей, которые внедряют её с умом, удержание заметно растёт уже в первые месяцы». Определение и конкретика — в первых двух предложениях.
2. Называем вещи своими именами — бренды, инструменты, платформы
Что делаем. Меняем обтекаемые формулировки на конкретные. «Интегрируемся с POS-системами» превращаем в «Интегрируемся с iiko, r_keeper, Poster и Quick Resto». Названия — это зацепки, по которым модель связывает текст с вопросом человека.
Как это выглядит. На странице про разработку рядом со стеком (React Native, монорепозиторий) мы называем агрегаторы — Яндекс Еда, Wolt, Glovo, Bolt Food. Так модель понимает контекст и выдаёт нас на запрос вроде «кто делает интеграции с агрегаторами».
3. Собираем страницу из самодостаточных H2-блоков
Что делаем. Каждый раздел под H2 должен держаться сам. Вырезали его со страницы — он всё равно понятен. Это и есть структура, удобная для RAG.
Как это выглядит. В статье «Технологический стек ресторана» раздел «Что такое POS-система» (определение, функции, примеры) спокойно цитируется отдельно — на запрос «что такое POS в ресторане». Наш разбор типов POS-систем так и собран.

Архитектура FoodTech-приложения на React Native: как собрать стабильный продукт и не утонуть в деталях
Читать статью4. Добавляем FAQ на каждую важную страницу
Что делаем. Формат простой: вопрос плюс ответ на два-четыре предложения, понятный сам по себе. ChatGPT, Claude и Perplexity цитируют такие ответы почти дословно — если они конкретные.
Как это выглядит. На странице «Разработка приложения для доставки» у нас стоит: «В: Сколько времени нужно на приложение для доставки? О: Базовый MVP — примерно 8–12 недель с выделенной командой. С интеграцией кассы и поддержкой нескольких точек — 14–20 недель. Главное тут не количество фич, а сложность интеграций».
5. Делаем /llms.txt и .md-версии ключевых страниц
Что делаем. /llms.txt — это Markdown-файл в корне сайта с картой главного контента. По сути robots.txt, только для LLM. Идею предложил в сентябре 2024-го Джереми Ховард из Answer.AI. Плюс делаем чистые .md-версии страниц, чтобы модель читала текст, не продираясь сквозь HTML.
Как это выглядит. В dev.family/llms.txt — короткое описание компании, ключевые страницы услуг с пояснениями и ссылки на кейсы. Чтобы Claude или ChatGPT при веб-поиске сразу понимали, чей это контент.
Что у нас не сработало (и не сработает у вас)
Мы перебрали кучу советов «как оптимизировать под AI» и часть честно попробовали. Несколько приёмов — пустая трата времени, рассказываем, чтобы вы на них не тратились.
- Разметка Schema.org / JSON-LD. В контролируемом эксперименте данные о товаре спрятали только в JSON-LD — и ChatGPT, Claude, Perplexity и Gemini их не увидели. Модели читают отрисованный текст, а не разметку. Исключение — Microsoft Copilot, он берёт понимание схемы из Bing. Структурированные данные оставьте ради Google, но роста AI-видимости от них не ждите.
- Мета-теги «под AI» (<meta name="ai-content-url">, <meta name="llms">). Спецификации нет, никто их не читает. Один даже отправили в стандарт HTML — закрыли с пометкой «not planned».
- HTML-комментарии с подсказками для AI. Большинство парсеров выкидывают комментарии ещё до обработки — модель их просто не видит.
- Подмена контента ботам по User-Agent. Отдавать разное в зависимости от того, кто пришёл, — это клоакинг, и Google за него наказывает. Правильный путь — content negotiation через заголовок Accept: text/markdown, когда клиент сам просит нужный формат.
- Отдельные «страницы для AI». Нормальный /llms.txt и чистый Markdown уже закрывают задачу. Страница с табличкой «для AI-ассистентов» особого отношения не получает.
GEO — область молодая, и не всё проверено на больших данных, врать не будем. Если совсем коротко: самодостаточные блоки, FAQ, статистика и конкретные названия работают точно; /llms.txt — разумная дешёвая ставка; фокусы с метаданными — мимо.
GEO для фудтеха — что цепляет AI именно в нашей нише
Общие принципы работают для всех. Но в фудтехе мы заметили пару сигналов, которые весят особенно много — и о которых общие гайды по GEO молчат.
- Конкретные названия — главный рычаг. Кассы (iiko, r_keeper, Quick Resto), агрегаторы (Яндекс Еда, Wolt, Glovo, Bolt Food), платёжки (ЮKassa, CloudPayments) — это ровно те слова, которые человек вбивает в ChatGPT. Назвали их на странице — дали модели прямую дорожку от вопроса к вам.
- Операционные цифры делают контент цитируемым. Диапазон комиссий агрегаторов, срок MVP в 8–12 недель, привлечённый клиентом раунд — всё это превращается в проверяемый, удобный для цитаты фрагмент. Наш текст про то, почему рестораны теряют на доставке и как это чинить, как раз держится на таких цифрах, а гайд по программе лояльности для ритейла — на метриках удержания.
- Сравнения цитируют на сравнительных запросах. «Своя доставка против агрегаторов», «какие бывают POS» — когда человек просит AI взвесить варианты, модель тянется к контенту, который уже оформлен как сравнение. Аккуратная таблица бьёт три абзаца текста.
- Кейсы с результатами работают как доказательство. Спросят AI «кто лучше сделает приложение для dark kitchen» — и модель опирается на кейсы с конкретными исходами. Как раз такой у нас есть.
Наш кейс: как мы перезапустили Sizl, dark kitchen из Чикаго
Sizl, сеть dark kitchen из Чикаго, пришла к нам с приложением на Kotlin Multiplatform. Технология мощная, но редкая: библиотек под неё мало, а тут ещё сменился CTO — выросли риски по поддержке и скорости релизов. Мы перевели приложение на React Native и пересобрали на монорепозитории: клиентское приложение, приложение курьера и инструмент поддержки живут в одной кодовой базе, но развиваются каждый своим темпом. После релиза команда Sizl показала продукт инвесторам и подняла раунд — $3,6 млн при оценке $12 млн post-money. Новые фичи теперь выкатываем в среднем за день-два — та самая скорость, на которой держится растущая сеть кухонь.
И вот в чём связь с GEO. Этот абзац сам по себе — готовая цитата. В нём есть компания, город, технологии (Kotlin Multiplatform, React Native, монорепозиторий) и конкретный проверяемый результат. Спросят AI «кто делает приложения для dark kitchen» — и такой плотный, с именами и цифрами кусок модель спокойно вставит в ответ. Поэтому мы и пишем кейсы плотно: с именами, цифрами и результатом, чтобы их было удобно цитировать.

Доставка, которая работает: как умное приложение делает дарк-китчены масштабируемым бизнесом
Читать статьюЧто мы вынесли для себя
- GEO — про цитирование, SEO — про ранжирование. Алгоритмы разные, инструменты местами общие. Нужны оба.
- Единица GEO — абзац, а не страница. RAG достаёт самодостаточные куски, поэтому каждый блок делаем отдельно стоящим.
- Начинаем с определений и цифр. Статистика подняла AI-видимость на ~33%, цитаты — на ~43%, а ссылки на авторитетные источники — до 115% у слабого контента (исследование GEO, Принстон и IIT Delhi).
- Конкретные названия — сильнейший сигнал в фудтехе. Называем кассы, агрегаторы и платёжки прямо.
- FAQ цитируют почти дословно. Ответ на 2–4 предложения с цифрой — готовая цитата.
- Фокусы с метаданными пропускаем. Schema.org, AI-мета-теги, HTML-комментарии для LLM бесполезны — лучше вложиться в текст.
- /llms.txt — дешёвая разумная ставка. Не гарантия, но час работы с понятным потенциалом.
Напоследок
Веб всегда любил контент, собранный под то, как его читают машины. Просто теперь в аудитории ещё и ChatGPT, Claude, Perplexity — приёмы поменялись, а принцип остался: делайте свой лучший контент понятным, конкретным и удобным для цитаты. Мы держим эти правила в голове на каждом продукте и каждой странице. Хотите, посмотрим свежим взглядом, где сейчас ваш фудтех-контент, — запишитесь на консультацию, разберём вместе.