



Всем привет, на связи dev.family. Хотим рассказать про интересный проект, над которым мы трудимся почти полгода, и до сих пор продолжаем. За это время в нем многое произошло, многое поменялось. Мы открыли для себя что-то интересное, успели набить шишек.
Немного о проекте
Итак, над чем же мы все-таки работали? На самом деле, этот вопрос в какой-то момент стал очень актуальным, как, например, у владельца корпорации McDonalds в свое время. Мы начинали проект как крипто-программу лояльности, которая предоставляет конечным потребителям вознаграждение за определенные действия, а клиентам — сбор аналитики по этим самым пользователям. Да, довольно поверхностно, но это не важно.

Начало работы
Нужно было разработать Shopify модули для подключения в магазинах на Shopify, портал для брендов, расширение для Google Chrome, мобильное приложение + сервер с БД (ну, собственно, без них никуда). В целом, с тем, что нам нужно, мы определились и начали работу.
Так как проект сразу предполагался большим, все понимали, что вырасти он может как Алеша Попович замедленного действия.

Было решено делать все «правильно» и «по-человечески». То есть все писать на одном языке — TypeScript. Чтобы все писали одинаково, и не было лишних изменений в файлах, линтеры (много линтеров), чтобы все было «легко» переиспользовать, — выносить ВСЕ в отдельные модули, и чтобы не украли под Github access token.
Таким образом, мы и начали:
- Репозиторий для линтеров и ts конфига отдельная (style guide).
- Репозиторий для мобильного приложения (react native) и расширение к Chrome (react.js) (вместе, так как они повторяют один и тот же функционал, только нацелены на разных пользователей).
- Для портала еще один репозиторий.
- Два репозитория для Shopify модулей.
- Репозиторий для блокчейн стафа.
- Репозиторий под API (express.js).
- Репозиторий под инфраструктуру.
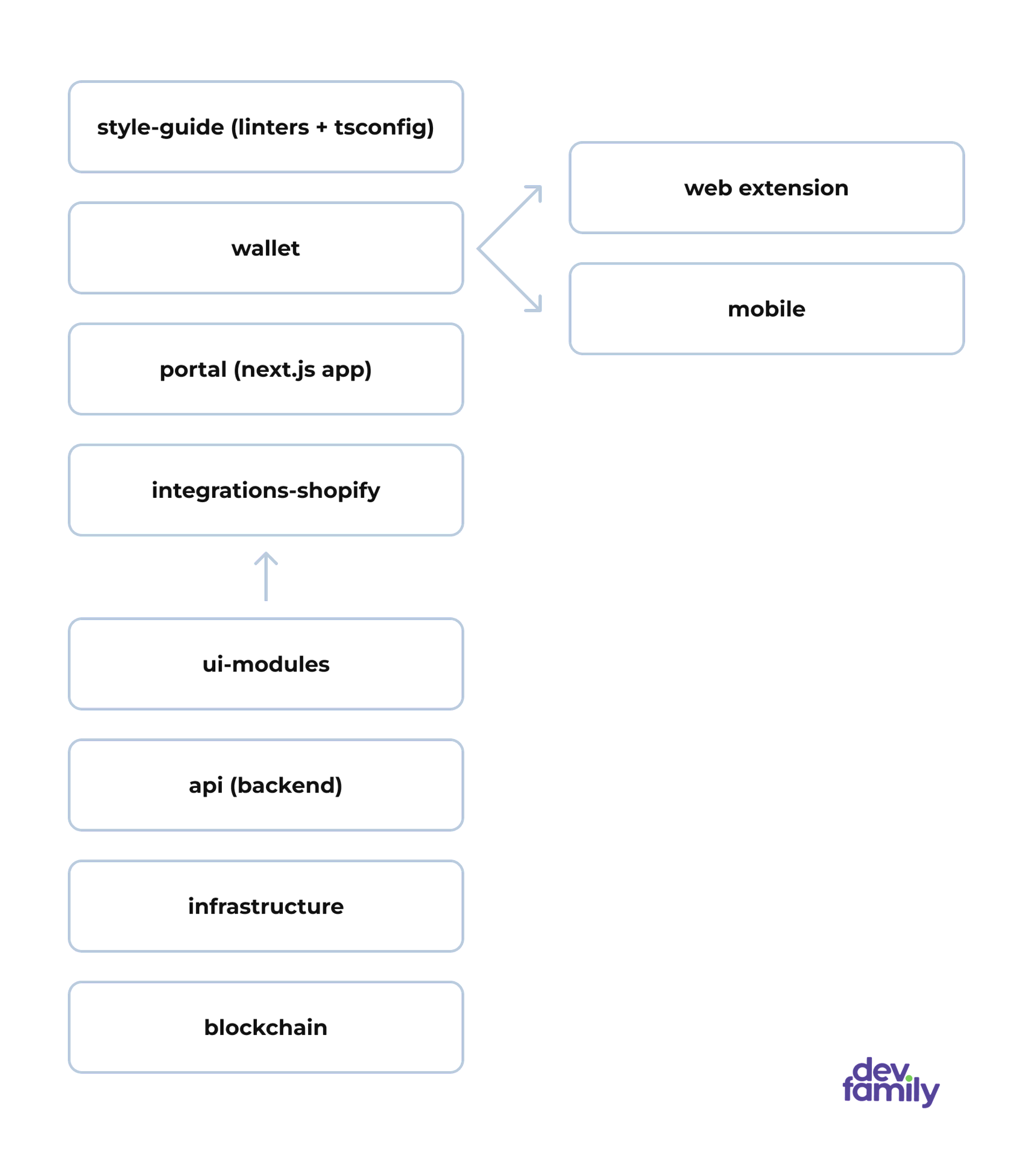
Фух… вроде, все перечислил. Вышло многовато, но ладно, живем. Ах, да, почему для Shopify модулей целых два репозитория было выделено? Потому что 1 репозиторий — это UI-modules. Там вся красота наших малышек и их настройки. А второй — integrations-Shopify. Это по факту сама их реализация в Shopify со всеми liquid файлами. Итого, у нас 8 репозиториев, где некоторые должны коммуницировать между собой.
Так как мы говорим про разработку на TypeScript, нам нужны и пакетные менеджеры для установки модулей, библиотек. Но мы все работали самостоятельно в своих репозиториях, и всем было без разницы, что использовать. Я, допустим, разрабатывая мобильное приложение на React Native, не долго думал и оставил YARN 1. Кому-то, возможно, привычнее использовать старый добрый NPM, а кто-то любил все новое и пользуется свежим YARN 3. Таким образом, где-то стоял NPM, где-то YARN 1, а где-то YARN 3.
Так мы все начали делать свои приложения. И почти сразу началось веселье, но не то, чтобы полное. Во-первых, некоторые не задумывались, для чего нужен TypeScript, и использовали Any везде, где им было лень, или где «не понимали», как можно его не писать. Кто-то не осознавал всю его силу и то, что в некоторых местах все можно сделать куда проще. Поэтому типы выходили космических размеров. Да, забыл сказать, в качестве базы данных решили использовать Hasura GraphQL. Ручная типизация всех ответов с нее порой выглядела, как то еще полотно. А в одном случае кое-кто и вовсе писал на старом добром Javascript. Да, ситуация вышла классная: одни Any ставят лишний раз, чтобы сильно не напрягаться, другие пишут полотна типов своими ручками, а третьи вообще не пишут типов.

Еще потом выяснится, что в случаях, где у нас повторялась логика, и, по-хорошему, ее стоило выносить в отдельный пакет, никто не собирался этого делать. Каждый себе код пишет и пишет, на все остальное — *** с высокой колокольни.
К чему нас это привело?
Что мы имеем? Мы имеем 8 репозиториев с разными приложениями. Какие-то нужны везде, другие общаются между собой. Поэтому все создаем .NPMrc файлы, прописываем креды, создаем github token, потом через пакетный менеджер модуль. В целом — несильная морока, хоть и неприятно, но ничего необычного.
Только в случае обновления чего-либо в пакете, надо повышать его версию, потом заливать, потом обновлять у себя в приложении/модуле, и только тогда ты увидишь, что изменилось. А вот это уже вообще ни в какие рамки! Особенно при условии, что можно просто поменять где-то цвет. Кроме этого, некоторый код повторяется и не переиспользуется, а просто спокойно переписывается. Если мы говорим про мобильное приложение и расширение для браузера, там полностью повторяется redux store и вся работа с API, что-то просто полностью переписано или немного видоизменено.
Итого, с чем мы остались: куча репозиториев, достаточно длительный запуск приложений/модулей, много одного и того же, написанного одними и теми же людьми, много потраченного времени на тест и на ввод в проект новых людей и другие проблемы, вытекающие из вышеперечисленного.

Короче, привело это нас к тому, что задачи выполнялись очень долго. Само собой, это привело к пропуску дедлайнов, вводить кого-то нового в проект было достаточно тяжело, что лишний раз сказывалось на скорости разработки. Собиралось все достаточно муторно и долго, в некоторых случаях, спасибо webpack’у.
Тогда стало понятно, что движемся мы далеко не туда, куда стремились, а невесть куда. Проанализировав все ошибки, мы приняли ряд решений, о которых сейчас и пойдет речь.
Почему монорепа?
Наверное, самое главное, что в дальнейшем на многое повлияло, — это осознание, что мы делаем не какое-то конкретное приложение, а именно платформу. У нас есть несколько типов пользователей, для них есть разные приложения, но действуют они в рамках одной платформы. Так мы сразу закрыли вопрос с большим количеством репозиториев: если мы работаем над одной платформой, зачем ее разбивать по репозиториям, когда проще работать в одном.
Хочу сказать, что работа в монорепе чертовски облегчила нам жизнь. Некоторые приложения или модули имели между собой прямую связь, и теперь со спокойной душой можно работать над ними на одной ветке в одном репозитории. Но это далеко не главный плюс.
Продолжим. Мы перенесли все в один репозиторий. Класс! Продолжили работать в том же темпе, пока дело не дошло до переиспользуемости. На самом деле, это является правилом хорошего тона в нашей работе. Осознав, что местами мы используем одни и те же алгоритмы, функции, код, а местами отдельные пакеты, которые ставили через github, мы решили что все это «не очень пахнет» и начали выносить все в отдельные пакеты в рамках монорепы с помощью Workspaces.
По факту это и есть пакеты в рамках одного пакета, которые линкуются через определенный пакетный менеджер (любой YARN/NPM/PNPM), а после используется в другом пакете. По правде говоря, мы не сразу все переписали на воркспейсы, а делали это по мере необходимости.
Как это выглядит?
Из одного файла:
{
"type": "module",
"name": "package-name-1",
...
"types": "./src/index.ts",
"exports": {
".": "./src/index.ts"
},
},В другой файл:
Пример с использованием PNPM
{
"type": "module",
"name": "package-name-2",
...
"dependencies": {
"package-name-1": "workspace:*",
},
},Ничего сложного, если так подумать: напиши пару команд и строк, а потом используй, что хочешь да где хочешь. Но «есть один нюанс, товарищи», как говорится. Ранее я писал, что каждый использовал тот менеджер, который хотел. Короче, появился у нас репозиторий с разными менеджерами. Местами было смешно, когда кто-то писал, что не может залинковать тот или иной пакет, при условии, что он использует NPM, а там стоит YARN.
Добавлю, что проблема была не из-за разных менеджеров, а из-за того, что люди использовали не те команды или не так что-то настраивали. Например, одни через YARN 3 делали просто YARN link и всё, а для YARN 1 это не работало так, как хотелось, из-за отсутствия обратной совместимости.
После перехода на монорепу:

Почему PNPM?
К этому моменту стало понятно, что использовать лучше один и тот же менеджер пакетов. Но нужно выбрать, какой именно, так на тот момент мы рассматривали только 2 варианта: YARN и PNPM. NPM мы откинули сразу, так он был медленнее других и уродливее. Оставался выбор между PNPM и YARN.
YARN изначально себя хорошо зарекомендовал — он был быстрее, проще и понятнее, поэтому все его тогда и использовали. Но человек, работавший над YARN’ом, ушел из Facebook, и разработку следующих версий передали другим. Так появились YARN 2 и YARN 3 без обратной совместимости с первым. Еще, помимо yarn.lock файла, они генерируют yarn папку, которая иногда весит как node_modules и хранит в себе кэши.
Поэтому мы, как и многие другие разработчики, обратили внимание на PNPM. Он оказался таким же удобным, как и первый YARN в свое время. Здесь можно легко использовать воркспейсы, некоторые команды выглядят так же как и в первом YARN. Кроме этого shamefully-hoist оказался приятной дополнительной опцией — ставить один раз node_modules сразу везде удобнее, чем каждый раз заходить в какую-то папку и делать PNPM install.

Turborepo и переиспользования кода
В дополнение мы решили попробовать turborepo. Turborepo — это тула для CI/CD, которая имеет свой ряд опций, cli, и конфигурацию через turbo.json файл. Устанавливается и настраивается максимально просто. Ставим глобально копию turbo cli через:
PNPM add turbo --globalДобавляем turbo.json в проект
turbo.json
{
"$schema": "https://turbo.build/schema.json",
"pipeline": {
"build": {
"dependsOn": ["^build"]
}
}
}После мы можем использовать все доступные функции turbo. Нас больше всего привлекли его плюшки и возможность использования в монорепе.
Что нас зацепило
- Incremental builds (Инкрементальные сборки — собирать билды достаточно болезненно, Turborepo запомнит то, что было сбилжено, и пропустит то, что уже было вычислено);
- Content-aware hashing (Хэширование с учетом содержимого — Turborepo смотрит на содержимое файлов, а не на временные метки, чтобы выяснить, что нужно сбилдить);
- Remote Caching (Удаленное хэширование — делиться удаленным кешем сборки с командой и CI/CD для еще более быстрой сборки.);
- Task pipelines (Конвейер задач, который определяет отношения между задачами, а затем оптимизирует, что и когда создавать.).
- Parallel execution (Параллельное выполнение — Выполняет сборки, используя каждое ядро с максимальным параллелизмом, не тратя впустую простаивающие ЦП).
Также из документации мы взяли рекомендацию по организации монорепы и имплементировали в нашу платформу. То есть разбили все наши пакеты на apps и packages. Для этого еще создаем файл PNPM-workspace.yaml и прописываем:
PNPM-workspace.yaml
packages:
- 'apps/**/*'
- 'packages/**/*'Тут можно посмотреть пример нашей структуры до и после:
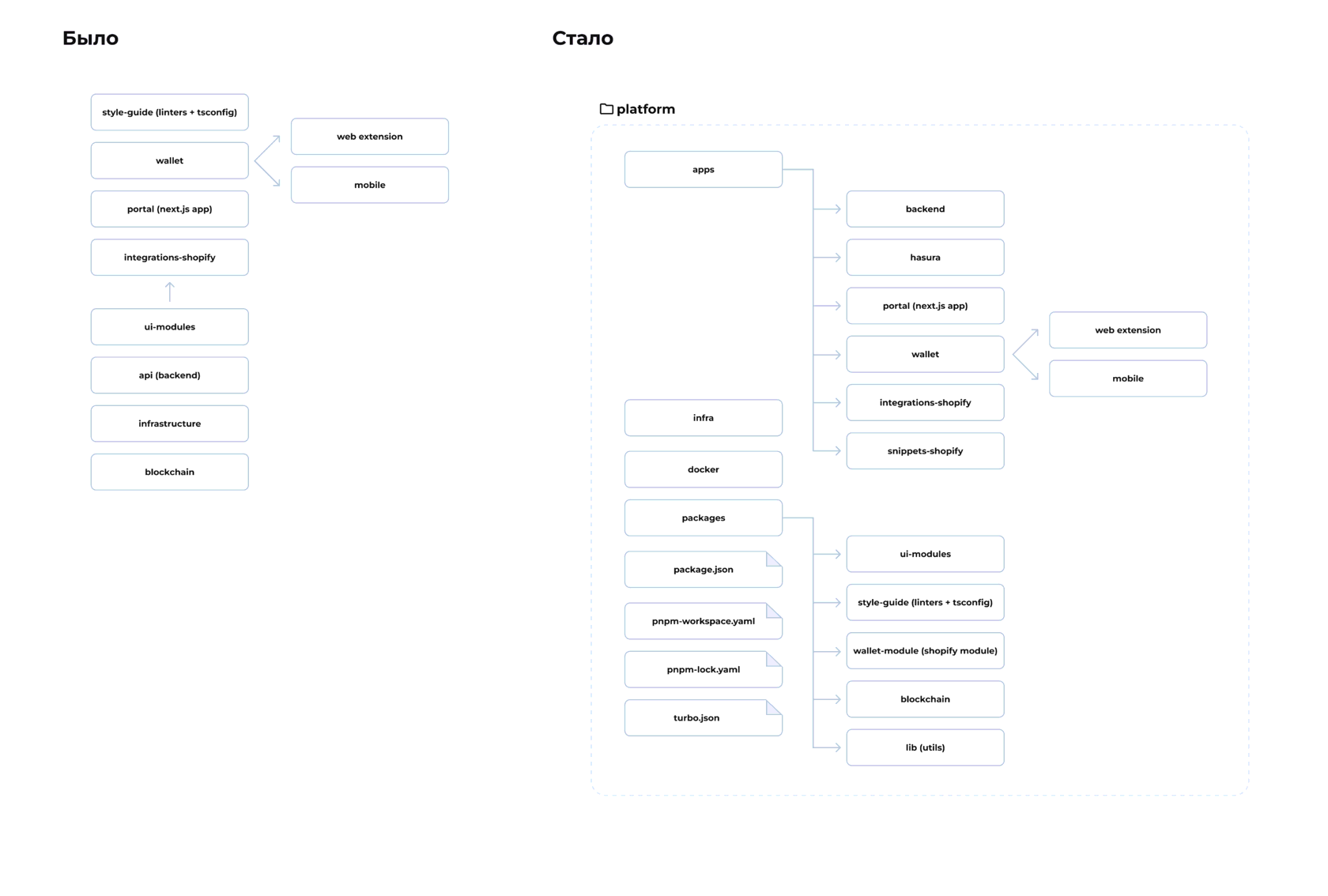
Теперь у нас есть монорепа с настроенными воркспейсами и удобным переиспользованием кода. Добавлю еще несколько пунктов, которые мы сделали параллельно. Ранее я упоминал два момента: у нас было расширение для хрома, мы решили, что делаем платформу.
Так как приоритетно наша платформа работала с Shopify, мы решили, что вместо расширение для Chrome или в дополнение к нему, хорошо бы сделать еще модуль к Shopify, который можно просто установить на сайт, чтобы лишний раз не заставлять людей скачивать мобильное приложение или Chrome extension. Но он должен полностью повторять расширение. Изначально мы делали их параллельно, но понимали, что делаем что то не правильно, потому что просто дублировали код. Во всех смыслах пишем одно и то же в разных местах. Но поскольку у нас теперь все воркспейсы и переиспользование настроены, мы легко вынесли все в один пакет, который вызвали в Shopify module и Chrome extension. Таким образом мы сэкономили себе кучу времени.
Теперь это и index.html весь Chrome extension:

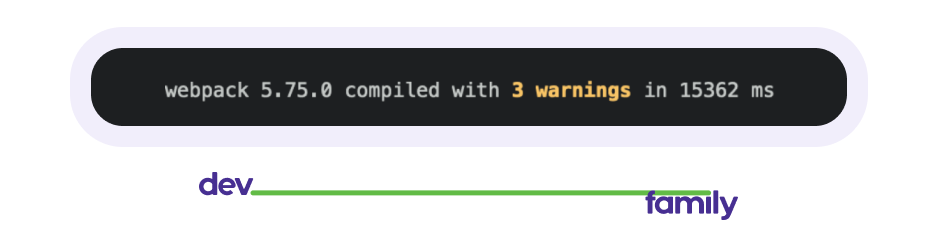
Второе, что сэкономило нам много времени, — отказ от webpack, а в некоторых местах от билдов в целом. Что не так с вебпаком? На самом деле есть два критичных момента: сложность и скорость. Что мы выбрали — vite. Почему? Его проще настроить, он быстро набирает популярность и уже имеет большое количество рабочих плагинов, а для установки хватает примера из доки. В сравнении билд на вебпаке нашего Chrome web extension занимал около 15 секунд, на vite.js:
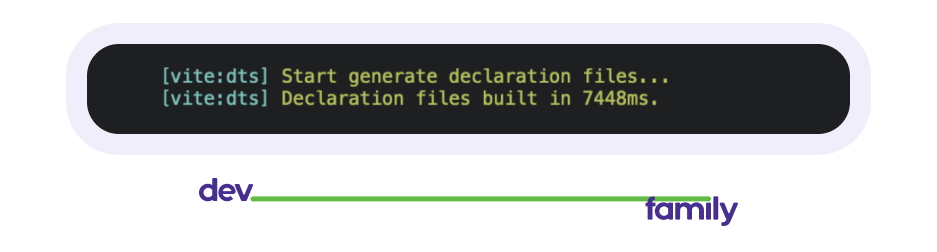
И около 7 секунд (с генерацией dts файла):
Разница ощутима. Что там с отказом от билдов? Все просто, как выяснилось, нам они не особо и нужны были, так как это переиспользуемые модули и в package.json, в exports можно было просто заменить dist/index.js на src/index.ts.
Было:
{
...
"exports": {
"import": "./dist/built-index.js"
},
...
}Стало:
{
...
"types": "./src/index.ts",
"exports": {
".": "./src/index.ts"
},
...
}Таким образом мы избавились от необходимости запускать PNPM watch для отслеживания обновлений приложения, связанных с теми модулями, и делать PNPM build, чтобы подтягивать обновления. Не думаю, что стоит объяснять, как это сэкономило нам время.
На самом деле одной из причин почему мы собирали билды был TypeScript, точнее index.d.ts файлы. Чтобы при импорте наших модулей/пакетов мы знали какие ожидаются типы в тех или иных функциях или какие типы нам вернут другие, как, например, здесь:
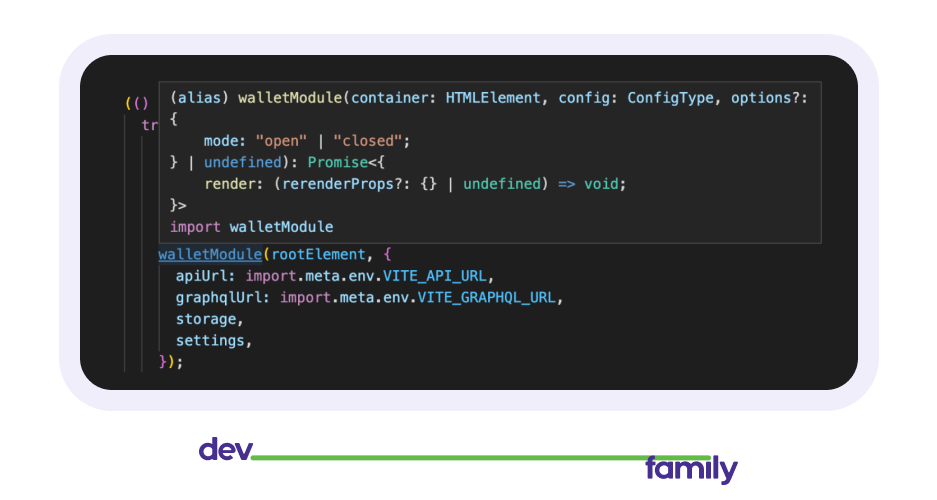
Но с учетом, что можно просто экспортировать из index.tsx, появилась еще одна причина отказаться от билдов.
TypeScript + GraphQL
Но все таки почему же TypeScript? Думаю, сейчас уже нет смысла расписывать все преимущества TS: безопасность типов, облегчение процесса разработки благодаря типизации, наличие интерфейсов и классов, открытый исходный код, ошибки, допущенные в процессе модификации кода, видны сразу, а не во время выполнения и так далее.
Как я говорил в самом начале, мы решили писать все на одном языке, чтобы, если кто-то перестанет работать или уйдет, можно было поддерживать или страховать. Сначала выбрали JS. Но JS не особо безопасен, и без тестов на крупных проектах весьма больно. Поэтому определились в пользу TS. Как показала практика, он весьма удобен в монорепе, благодаря тому, что можно просто экспортировать *.ts файлы, а при использовании компонентов сразу понятны ожидаемы для них данные и их типы.
Но одной из главных полезных фишек была автогенерация типов для GraphQl query и мутаций. Для всех, кто не сильно осведомлен, GraphQl — такая технология, которая позволяет ходить в БД через те самые query(для получения данных) и mutation(для изменения данных), и выглядит примерно так:
query getShop {
shop {
shopName
shopLocation
}
}В отличие от REST API, где пока не получишь — не узнаешь, что тебе придет, здесь ты сам определяешь данные, которые тебе нужны.
Вернемся к нашим баранам. Мы использовали Hasura, которая представляла собой GraphQL обертку поверх PostgreSQL. Раз мы работаем с TS, то по-хорошему должны типизировать данные и с запросов, и те, что мы отправляем в payload. Если мы говорим о коде из примера выше, проблем не должно возникнуть, вроде как. Только на деле query может выйти на сто строк, плюс некоторые поля могут как прийти, так и не прийти, или иметь разные типы данных. А типизировать такие полотна — весьма долгое и неблагодарное дело.
Альтернатива? Конечно есть! Пусть типы генерируются через команды. На нашем проекте мы делали следующим образом:
- Мы использовали следующие библиотеки: graphql и graphql-request.
- Сначала создавали файлы с разрешением *.graphql, в которых прописывали query и мутации. Например:
test.graphql
query getAllShops {
test_shops {
identifier
name
location
owner_id
url
domain
type
owner {
name
owner_id
}
}
}- Дальше создавали codegen.yaml:
codegen.yaml
schema:
- ${HASURA_URL}:
headers:
x-hasura-admin-secret: ${HASURA_SECRET}
emitLegacyCommonJSImports: false
config:
gqlImport: graphql-tag#gql
scalars:
numeric: string
uuid: string
bigint: string
timestamptz: string
smallint: number
generates:
src/infrastructure/api/graphQl/operations.ts:
documents: 'src/**/*.graphql'
plugins:
- TypeScript
- TypeScript-operations
- TypeScript-graphql-requestТам указывали, куда обращаемся, а в конце — то, куда сохраняем файл со сгенерированной API (src/infrastructure/api/graphQl/operations.ts) и то, откуда берем наши запросы (src/**/*.graphql).
- После этого в package.json добавляли скрипт, который генерировал нам те самые типы:
package.json
{
...
"scripts": {
"generate": "HASURA_URL=http://localhost:9696/v1/graphql HASURA_SECRET=secret graphql-codegen-esm --config codegen.yml",
...
},
...
}Там указывали URL, по которому обращается скрипт для получения информации, секрет и саму команду.
- В конце создаем клиент:
import { GraphQLClient } from "graphql-request";
import { getSdk } from "./operations.js";
export const createGraphQlClient = ({ getToken }: CreateGraphQlClient) => {
const graphQLClient = new GraphQLClient(‘your url goes here...’);
return getSdk(graphQLClient);
};Таким образом, получаем функцию, которая генерирует клиент со всеми query и мутациями. Бонусом в operations.ts лежат все наши типы, которые мы можем экспортировать и использовать, и есть полная типизация всего запроса: мы знаем, что надо отдать и что придет. Больше ни о чем думать не нужно, кроме как запустить команду и наслаждаться прелестью типизации.
Заключение
В итоге мы избавились от большого количества ненужных репозиториев и необходимости постоянно пушить малейшие изменения, чтобы проверить, как что работает. Вместо этого пришли к одному, в котором всё структурировано разложено по своему назначению и все легко переиспользуется. Так мы облегчили себе жизнь и сократили время на ввод новых людей в проект, на запуск платформы и модулей/приложений по-отдельности. Все типизировали, и теперь не надо лезть в каждую папку и смотреть, чего хочет та или иная функция/компонент. Как результат — сократили время на разработку.

В заключение хочу сказать, что никогда не стоит торопиться. Лучше понять, что вы делаете, и как это сделать проще, чем специально усложнять себе жизнь. Проблемы есть везде и всегда, рано или поздно они где-то вылезут, и тогда намеренное усложнение выстрелит вам в колено и никак не поможет. С вами была команда dev.family, до связи!














