Дано
Компания dev.family – разработчики на аутсорсе, специализируемся на ecomm и фудтехе, делаем кроссплатформенный мобайл и веб.

Одновременно у нас в разработке около 10 проектов, плюс есть старые, которые мы поддерживаем. Когда мы задумали весь этот «переворот», описанный в статье, то шли к тому, чтобы после каждого коммита в мастер ветку, она автоматически разворачивалась. Чтобы по желанию можно было независимо развернуть другие ветки, деплоить на продакшн. В нашей новой картине мира мы не должны были страдать из-за наличия разных версий ПО, https мог выписываться автоматом, а старые и ненужные ветки со временем бы удалялись. И все это ради того, чтобы мы могли сфокусироваться на разработке и не тратить время на развертывание каждого проекта на тестовой площадке.
Как и многие, давным-давно мы все деплоили ручками. Заходили на сервер, git pull, выполняли команды миграции. Потом вспоминали, что при миграции забыли выполнить какую-то команду, что-то поломалось и пошло-поехало.
А еще в процессе можно было и полежать, пока сайт обновлялся, так как код, например, мог уже обновится, а миграция в базе данных — нет. И упаси боже, если у нас dev, stage, prod! На каждый зайди, ручками разверни. А как-то мы захотели развернуть несколько веток параллельно и тоже пришлось вручную…Кошмар, страшно вспомнить, но ностальгия приятная.
Со временем это стало вызвать кучу проблем:
- разные версии php, node.js;
- некоторые приложения требовали установки утилит прямо в систему;
- разница локального окружения и продакшена. То, что работало при разработке, могло поломаться после деплоя на прод;
- сложно было запускать старые проекты, которые имели множество зависимостей
Короче говоря, решили мы, что пора бы все это упаковать в docker...

Что мы сделали?
Где-то в 2018 мы обратили внимание на Docker, потому что увидели в нем ключ к решению этих проблем. Решили внедрять его постепенно, и только в новые проекты. Поэтому процесс занял довольно длительное время. А когда Kubernetes и практики ci/cd стали набирать популярность, решили их использовать для тестового окружения.
Причинами использования Kubernetes на наших проектах стали:
- автоматическая выдача сертификатов;
- масштабирование
- высокая доступность;
- удобство управления контейнерами.
Kubernetes предоставлял готовое решение для этих задач и позволил нам быстро и эффективно решать соответствующие проблемы.

Для для ci/cd мы использовали GitLab Runner, так как проекты храним в собственном GitLab Instance. Kubernetes поднимался через microk8s.
Деплой происходил с помощью helm. Такое решение просуществовало долго, но рождало много проблем:
- Для надежной работы кластера Kubernetes, требуется минимум 3 ноды, у нас была только одна.
- Быстрое развитие Kubernetes и сложности, связанные с его обновлением.
- Огромные yaml, которые сложно читать, создавать и поддерживать.
- Требуется много времени на обучение, и решение всякого рода проблем. Выделенной команды devops у нас нет.
Однако опыт использования Kubernetes был очень полезен, и мы всегда держим в уме, что при увеличении нагрузки на приложение, можем обратится к этому инструменту.
К чему мы пришли в итоге?
Устав бороться с постоянными проблемами и сложностью Kubernetes, стали искать альтернативу. Рассматривали Swarm и другие решения, но ничего лучше чем Docker Compose не нашли. На нем и остановились.
Почему? Да потому что каждый разработчик в компании умеет работать с Docker Compose. С ним сложно выстрелить себе в ногу, его легко поддерживать и разворачивать. А его минусы практически не заметны на наших проектах.
К минусам я отношу:
- Масштабирование: Docker Compose не имеет встроенных инструментов для масштабирования приложений.
- Ограничение ресурсов: Docker Compose не дает возможности ограничить потребление ресурсов в рамках одного контейнера.
- Отсутствие обновлений без простоя. Во время обновления приложение в Docker Compose оно на пару секунд становится недоступно.
Потом стали искать решение для деплоя в dev-окружение. Главное, что нам требовалось, — чтобы каждая ветка был доступна по своему адресу и получала сертификат для https.
Готового решения найти не удалось, по этому реализовали собственный деплоер.
Что мы придумали для деплоя?
Схема нашего деплоера выглядит следующим образом:
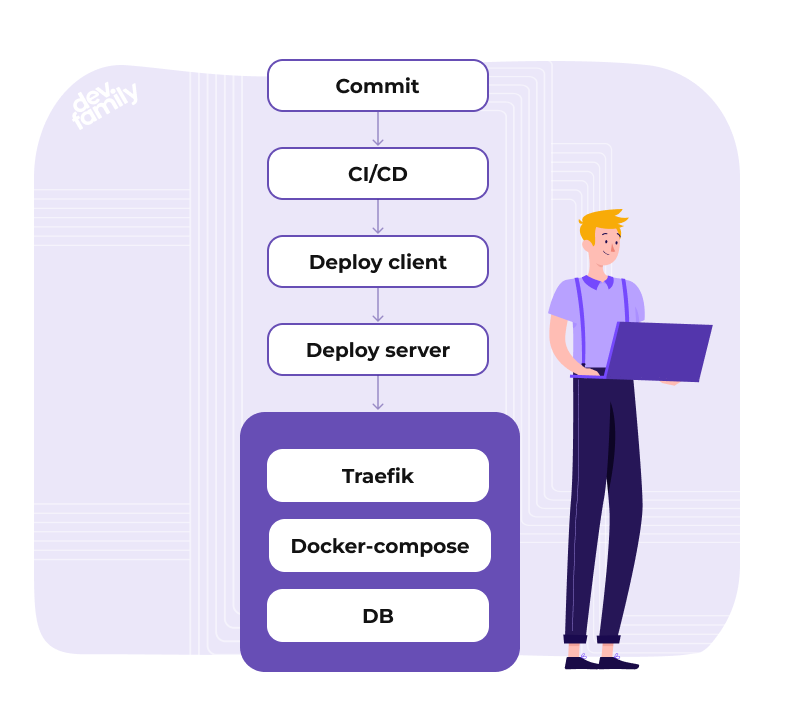
Deploy client и deploy server — это два бинарника, написанные на golang. Клиент запакован в docker и размещен в registry нашего GitLab.
Все, что делает client, — это берет все файлы из директории, и отправляет их на deploy server по http. Вместе с файлами, отправляет еще и переменные GitLab. В ci/cd это выглядит так:
review:
image: gitlab/company/ci-deployer/client:latest
stage: review
script:
- deploy
//прочий код
function deploy() {
mv ci/dev /deploys;
/golang/main up;
}Deploy server же запущен как демон и принимает файлы по http. Базовая структура файлов выглядит таким образом:
config.json
Содержит конфигурацию. Пример:
{
"not_delete_old" : false, //проекты, в которые не пушили 28 дней удаляются
"cron": {
"enable": true, //настройка крон команд
"commands": [
{
"schedule": "* * * * *",
"task": "cron" //будет выполнена таска из Taskfile.yml
}
]
}
}Taskfile.yml
Содержит задачи, которые будут выполнятся при деплое. В системе установлена утилита.
version: '3'
tasks:
up:
cmds:
- docker-compose pull
- docker-compose up -d --remove-orphans
- docker-compose exec -T back php artisan migrate --force
- docker-compose exec -T back php artisan search:index
down:
cmds:
- docker-compose down
cron:
cmds:
- docker-compose exec -T back php artisan schedule:run
tinker:
cmds:
- docker-compose exec back php artisan tinker.env
Переменные окружения для Docker Сompose.
COMPOSE_PROJECT_NAME={{ .BaseName }}
VERSION={{ .Version }}
REGISTRY={{ .RegImage }}docker-compose.yaml
version: "3.8"
services:
front:
networks:
- traefik
restart: always
image: ${REGISTRY}/front:${VERSION}
env_file: .env.fronted
labels:
- "traefik.enable=true"
- "traefik.http.routers.{{ .BaseName }}.rule=Host(`vendor.{{ .HOST }}`)"
- "traefik.http.routers.{{ .BaseName }}.entrypoints=websecure"
- "traefik.http.routers.{{ .BaseName }}.tls.certresolver=myresolver"
- "traefik.http.routers.{{ .BaseName }}.service={{ .BaseName }}"
- "traefik.http.services.{{ .BaseName }}.loadbalancer.server.port=3000"
networks:
traefik:
name: app_traefik
external: trueПриняв файлы, сервер начинает свою работу. На основании переменных GitLab, среди которых есть название ветки, проекта и прочее, создаются переменные для развертывания . BaseName создается таким образом.
return fmt.Sprintf("%s_%s_%s",
receiver.EnvGit["CI_PROJECT_NAMESPACE"], //группа проекта
receiver.EnvGit["CI_PROJECT_NAME"], //название проекта
receiver.EnvGit["CI_COMMIT_BRANCH"], //название ветки
)Все файлы обрабатываются как шаблоны golang. Поэтому, например, в docker-compose.yaml вместо {{.BaseName}} будет подставлено созданное уникальное имя для развертывания. {{.HOST}} также строится на основании названия ветки.
Далее создается база данных для ветки, если она не была создана. Если ветка отличная от main, то БД не создается с нуля, а клонируется main база. Это удобно, так как миграции в ветке не затрагивают main. А вот данные из main в ветке могут быть полезны.
После этого, уже готовые файлы размещаются в директорию, по пути
/группа проекта/название проекта/название веткиИ выполняется команда в системе task up, которая описана в файле Taskfile.yml . В ней уже описываются команды под конкретный проект.
После чего, развертывание становится доступно в сети traefik, который автоматически начинает проксировать на него трафик и выдает сертефикат let's encrypt.
Что мы имеем в итоге?
- Такой подход сильно упростил разработку: стало легче использовать различные новые утилиты, которые легко добавить как еще один сервис в docker-compose.yaml. И теперь каждый разработчик понимает, как работает тестовое окружение.
- Эту систему легко подстроить конкретно под наши нужды. Например, нам понадобилось добавить возможность запускать крон. Решение очень простое. Создаем конфигурацию через config.json, парсим его в golang структуру и уже внутри сервера запускаем крон, который динамически можно изменять.
- Еще была реализована одна из идей: выключать неактивные проекты, в которые не пушили больше 28 дней. Для этого создали файл с данными о последнем развертывании.
"XXX_NAME": {
"user": "xxxx",
"slug": "xxxx",
"db": "xxx",
"branch": "main",
"db_default": "xxxxx",
"last_up": "2023-04-07T09:06:15.017236822Z",
"version": "cb2dd08b02fd29d57599d2ac14c4c26200e3c827",
"dir": "/projects/xxx/backend/main",
},
Далее уже крон внутри server deployer раз в день проверяет этот файл, если видит в нем неактивный проект, идет в dir и выполняет команду down. Ну и удаляет базу данных, если это не main ветка. А для информативности, сервер после выполнения работы отдает логи клиенту, который их отображает в GitLab.
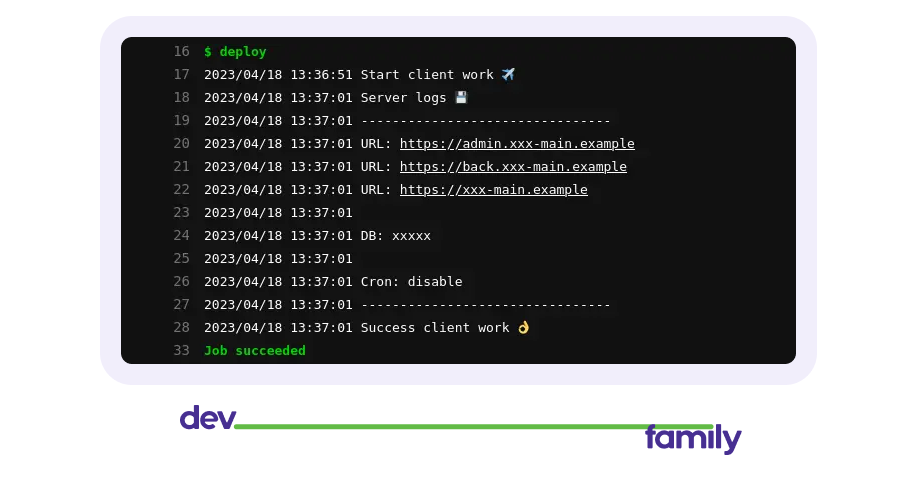
Выглядит это так, когда все хорошо
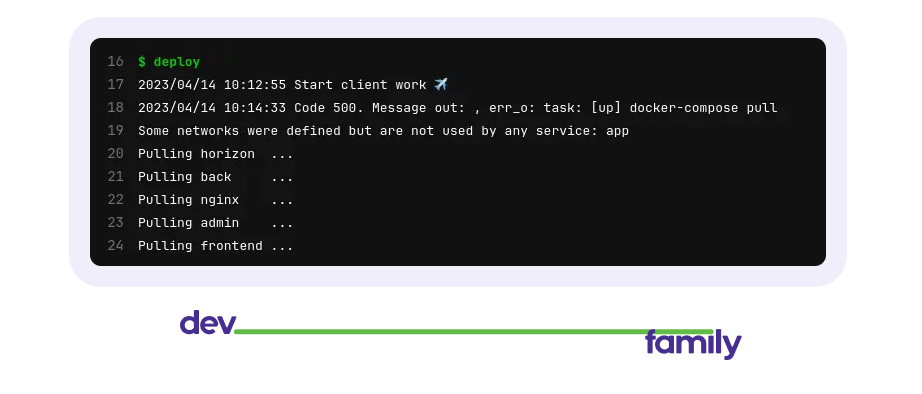
Ну или так, когда что-то пошло не так :)