



Итак, вы сделали всё по учебнику: протестировали идею, собрали и проверили MVP, получили первые заказы и даже отзывы бета-пользователей. Кухня работает, курьеры на маршруте, корзины пополняются – кажется, можно открывать шампанское.
Но наступает вечер пятницы — и всё идёт не по плану: акция «2 по цене 1» валит сервер, курьеры не могут обновить статусы заказов из-за плохого интернета, крупный корпоративный заказ ломает оформление, а платежи замирают именно тогда, когда терминал должен работать без остановки. Минуты превращаются в потерянные заказы, остывшую еду, сорванные смены и недовольство клиентов.

Мелочи, которые не заметили на старте, часто убивают классные проекты быстрее, чем это успевают сделать конкуренты.
И чтобы этого не произошло, стоит задать себе несколько вопросов:
- Что будет, если приложение закроется само по себе в момент, когда клиент оформляет заказ?
- Почему во время распродажи склад может перестать обновлять остатки?
- Будет ли зависать приложение на старых моделях смартфонов?
- Куда исчезает заказ клиента, если приложение не может отправить данные на сервер из-за плохой связи?
- Насколько увеличится время обработки каждого заказа из-за «невидимой» технической ошибки?
Мы проанализировали наши последние проекты и собрали шесть технических нюансов, которые могут убить даже перспективный продукт. О них часто не думают ни стартапы, ни опытные бизнесы – пока не становится слишком поздно. Расскажем, как сделать так, чтобы ваше приложение не рухнуло в самый неподходящий момент.
Offline-first: приложение, которое не зависит от сети
Почему заказ так и не доехал вовремя? Часто причина банальна: многие процессы внутри приложении завязаны на соединении с интернетом. Стоит ему пропасть, и весь флоу прерывается. Мы видели это видели на складах, где сканер штрихкода зависает из-за слабого Wi-Fi, на доставках, когда курьер заезжает в «мертвую зону» и статус заказа невозможно обновить в системе, на пунктах выдачи, где QR-код не пробивается, пока не вернётся соединение.
И в ходе разработки приложения для курьеров дарк-китчена Sizl в Чикаго заранее подумали об этом. При выполнении бесконтактной доставки курьер обязан отправить фото заказа, оставленного у двери, чтобы менеджер мог подтвердить завершение. Но без стабильного курьера соединения фото просто «зависало» в телефоне курьера, заказ не закрывался, а новые не уходили в работу.
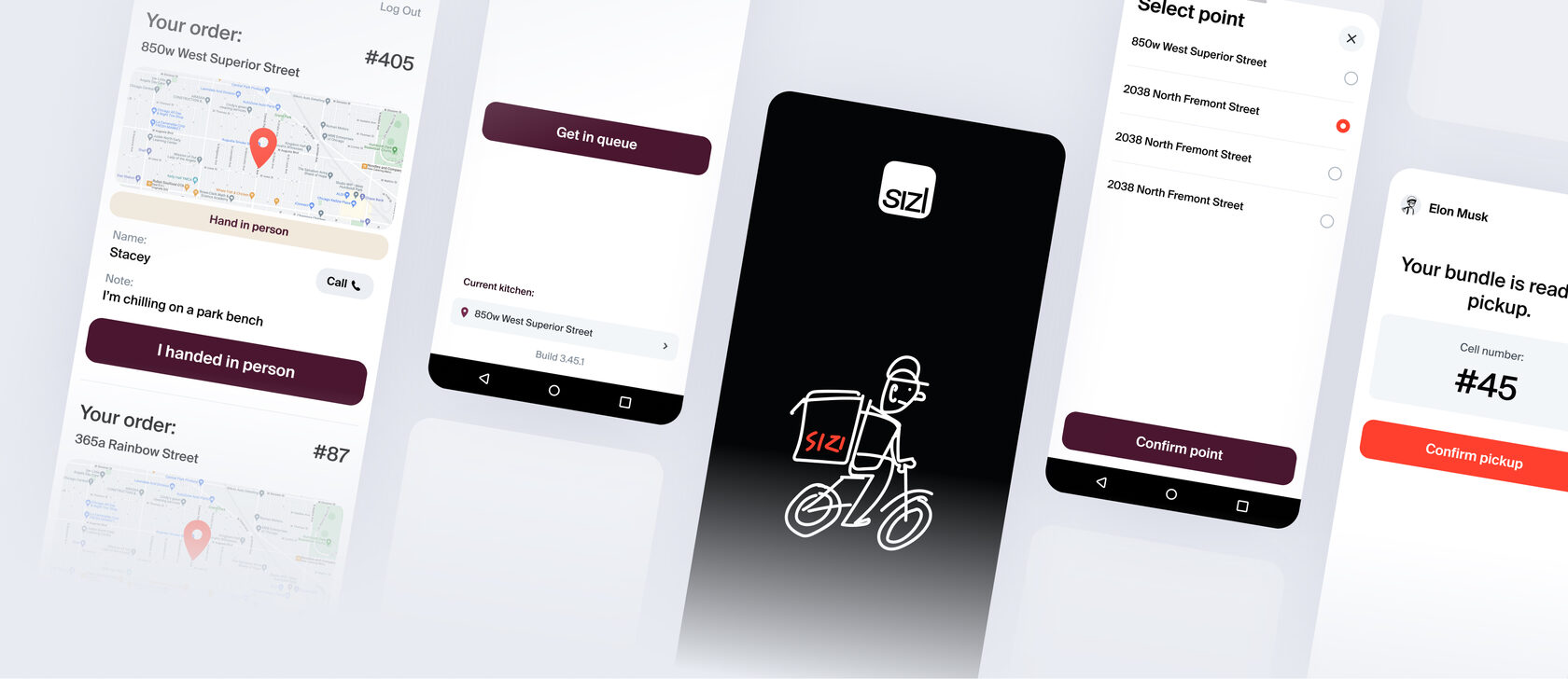
✍ Как подготовиться заранее
Использовать подход offline-first, при котором ключевые функции работают локально, без необходимости постоянного соединения с сервером. Если заложить его на старте проекта, приложение будет сохранять данные, даже если интернет временно пропал.Такая архитектура включает:
- Локальное хранилище — всё, что делает пользователь (фото, изменения статуса, чеки, сканы), сначала сохраняется на устройстве: в памяти телефона или в базе данных вроде SQLite.
- Очередь синхронизации — каждое действие ставится в «лист ожидания» и получает отметку времени.
- Фоновая отправка — как только связь восстанавливается, приложение автоматически «прогоняет» очередь и отправляет все данные на сервер, сохраняя их в том же порядке, что и офлайн.
- Механизм повторных попыток — если синхронизация по какой-то причине не удалась (например, файл слишком большой или сервер ответил с ошибкой), приложение пробует снова, пока не получит подтверждение.
Как реализовать offline-first подход с помощью React Native и RxDB, мы подробно описали в этой статье.

React Native + RxDB: как строить Local-First приложения. Архитектура и примеры
Читать статьюДля пользователя это значит одно: он может продолжать работать, не думая о сети. А для бизнеса – что процесс не «зависнет» из-за случайного обрыва связи, будь то в метро, в подвале склада или в пригороде с плохим покрытием.
Пик трафика без сбоев: что даёт нагрузочное тестирование
Быстрый рост – не подарок, а самый дорогой нагрузочный тест. Рекламную кампанию можно запустить за час, но перестроить архитектуру под возросший трафик – уже нет. Дело в том, что трафик приходит не равномерно, а волнами. И если система не спроектирована под такие нагрузки, успех превращается в поломки и простой: корзины начинают грузиться вечно, оформление заказа отвечает с ошибками, база данных задыхается от одинаковых запросов, а очередь на оплату превращается в пробку.
✍ Как подготовиться заранее
Наплыв трафика не спросит, готовы ли вы. Он просто придёт и проверит вашу систему на прочность. Чтобы в этот момент всё работало, тестировать и усиливать архитектуру нужно заранее, пока волна клиентов ещё не дошла до серверов. Вот что важно сделать:
- Протестируйте работу на максимальной нагрузке – имитируйте акцию или распродажу в рамках нагрузочного тестирования, чтобы понять, при каком объёме заказов система замедляется и где именно узкие места.
- Заложите запас мощности – настройте авто-масштабирование в облаке, чтобы при росте трафика система автоматически получала дополнительные ресурсы.
- Уберите лишние походы в базу – кэшируйте популярные данные (меню, карточки, цены), раздавайте их через CDN.
- Развяжите тяжёлые операции – пусть оформление заказа выполняется сразу, а вся «тяжёлая» обработка (уведомления, аналитика, генерация чеков) в порядке фоновой очереди.
- Следите и реагируйте – системы мониторинга с уведомлениями о превышении заранее заданного порога заказов станет сигналом ко включению планов B/C до того, как всё упадёт.
Сдерживать наплыв помогают и фишки в UI/UX самого приложения. Например, в клиентском приложении Sizl мы добавили специальную плашку, которая отображается в пиковые часы, чтобы снизить количество потенциальных заказов и разгрузить кухню и курьеров.
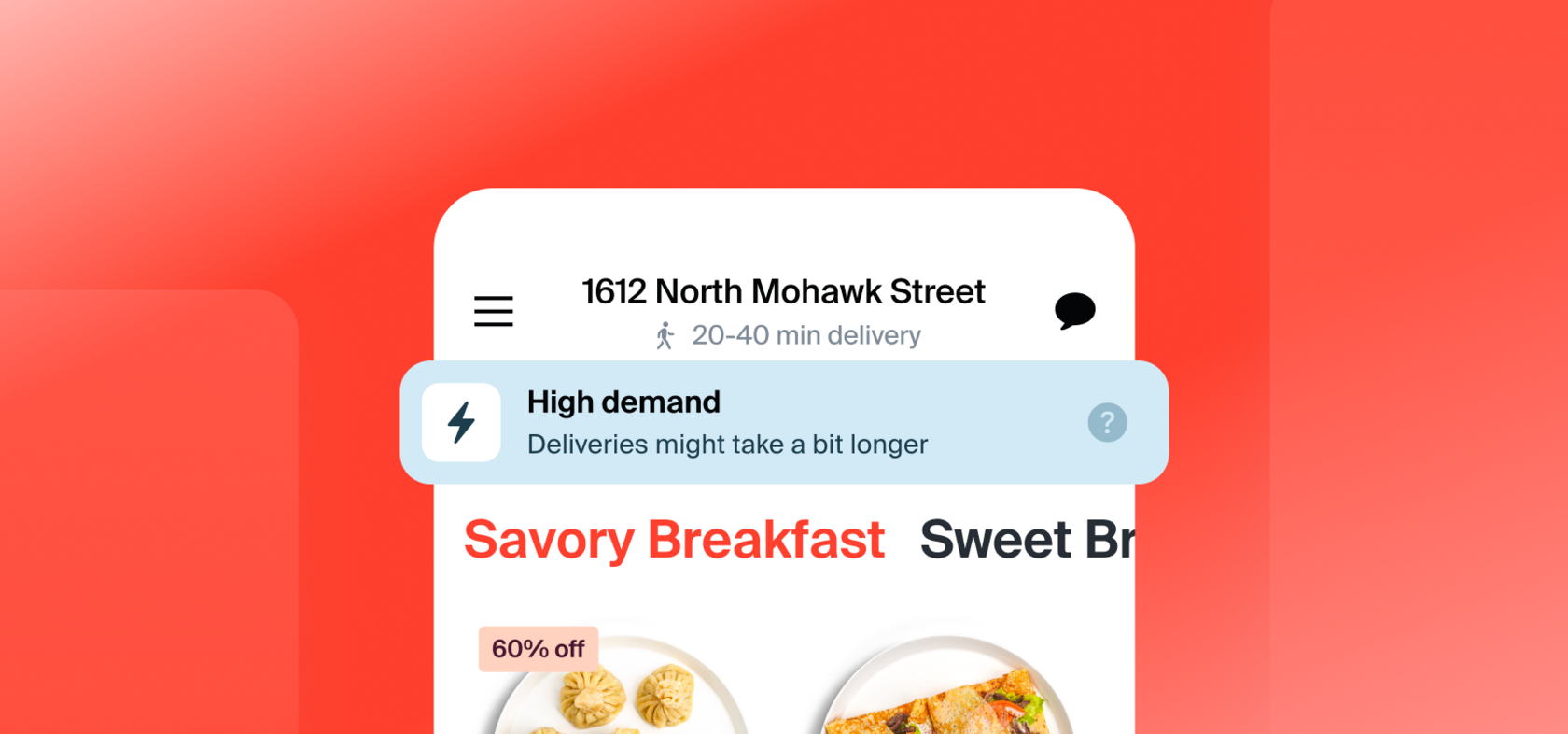
Про другие особенности дарк китчена Sizl читайте в нашем кейсе.
Защита от ввода неожиданных данных
Кажется, вы предусмотрели всё. Но пользователь – лучший тестировщик хаоса: он всегда найдёт кнопку, которую вы не проверяли, или введёт данные в таком виде, о котором разработчики даже не догадывались.
Технические системы любят порядок: чёткий формат номера телефона, корректные адреса, ожидаемые ответы от серверов. Но реальный мир – нет. Один лишний символ в адресе, неожиданный формат данных от внешнего сервиса, опечатка в имени или нестандартный символ — и приложение уже не знает, что делать дальше.
✍ Как подготовиться заранее
Главная задача – сделать так, чтобы ошибки пользователя не остановили работу приложения и не испортили опыт клиента. Для этого важно заранее предусмотреть защитные сценарии:
- Организуйте валидацию данных на входе – любая форма и любой ввод должны проверяться на допустимые символы, длину, формат;
- Продумайте fallback-сценарии – если внешний сервис вернул «кривой» ответ или не ответил вообще, подставить запасной вариант, а не останавливать процесс;
- Говорите с пользователем на его языке – сообщение «Сервис временно недоступен» работает лучше, чем «Error 500»;
- Ловите неожиданные сбои в коде – используйте конструкции вроде try/catch, которые позволяют «поймать» ошибку до того, как она сломает весь процесс, и выполнить запасной сценарий.
Поэтому, даже если клиент введёт в поле «Адрес» смайлик с пиццей, заказ не исчезнет, а приложение спокойно отработает ситуацию и проведёт его до конца.

Стабильная работа без утечек памяти
Не все сбои громкие. Некоторые начинают с еле заметных замедлений, но позже превращаются в полный паралич системы. Утром кассовое приложение открывает заказы без заметных задержек, а к вечеру обработка каждого клика занимает несколько секунд. Маркетплейс в первый час работает быстро, но после длительного просмотра каталога страницы начинают загружаться ощутимо медленнее. Складская система стабильно работает в начале приёмки, но через пару часов реагирует всё дольше на каждое действие.
✍ Как подготовиться заранее
Избежать медленной деградации приложения можно, если заранее заложить контроль за использованием памяти и регулярно проверять, как оно ведёт себя при длительной работе. В этом помогут следующие действия:
- Тесты длительной работы – прогоняйте приложение часами, имитируя реальную нагрузку, чтобы поймать баги, которые проявляются только «на дистанции»;
- Профилирование памяти – Android Studio Profiler, Xcode Instruments и аналоги показывают, что остаётся в памяти после каждого действия;
- Оптимизация больших данных – не держите в памяти огромные изображения или массивы – подгружайте их частями по мере необходимости.
- Освобождение ресурсов – закрывайте соединения, удаляйте объекты, выгружайте неиспользуемые данные.
В результате приложение остаётся стабильным, а оформление заказа проходит без ошибок и зависаний.
Устойчивость к сбоям интеграций
Современные приложения редко работают в изоляции – они плотно завязаны на внешние API: карты, платежи, геолокацию, системы уведомлений, проверки штрихкодов. Это удобно, пока всё работает. Но стоит одному звену оборваться, и весь процесс приостанавливается.
В доставке завис платёжный сервис, и корзина превращается в бесконечный «Loading…». В маркетплейсе падает картографический API, и пользователи больше не видят точки самовывоза. На складе «молчит» база штрихкодов, приёмка стопорится, заказы копятся, сотрудники злятся.
Внешние сервисы – это часть вашей системы, но их сбой не обязан парализовать весь процесс. Задача архитектуры – обеспечить работу приложения даже в таких условиях.
✍ Как подготовиться заранее
Вы не можете управлять внешними сервисами, но можете контролировать, как ваше приложение реагирует на их сбой. Для этого можно предусмотреть:
- Graceful degradation. Если сервис недоступен, приложение должно продолжать работать. Например, показывать кэшированные данные или честно сообщать: «Сервис временно недоступен, попробуйте позже».
- Очереди задач. Всё, что сейчас нельзя выполнить (отправка оплаты, загрузка фото), ставится в очередь и отправляется автоматически, как только связь восстановится.
- Таймауты и мониторинг. Система быстро понимает, что сервис «молчит», и не держит пользователя в вечной загрузке.
- Circuit Breaker. Этот шаблон позволяет временно отключить зависший сервис, чтобы он не блокировал остальной функционал.
В итоге сбой партнёра остаётся его проблемой, а ваш бизнес и пользователи продолжают работать без ощущения, что «всё сломалось».
Посмотрите, как мы организовали интеграции со сторонними сервисами для маркетплейса Godno.
5 главных выводов для подготовки к росту и нагрузкам
Чтобы рост трафика, непредсказуемые действия пользователей или падение сторонних сервисов не обернулись кризисом, закладывайте устойчивость ещё на этапе проектирования:
- Проектируйте с учётом нестабильного соединения. Подход offline-first позволяет ключевым функциям работать локально и синхронизироваться с сервером при восстановлении сети. Это спасёт процессы в доставке, складской логистике и любых сценариях с выездной работой.
- Закладывайте масштабируемость с первого дня. Планируйте архитектуру и инфраструктуру так, чтобы они выдерживали кратный рост аудитории без «просадок». Автоматическое масштабирование, нагрузочные тесты и оптимизация запросов – обязательная часть подготовки.
- Обрабатывайте ошибки проактивно. Валидация данных на входе, резервные сценарии и понятные сообщения пользователю снижают риск сбоев из-за неожиданных форматов, опечаток или падения интеграций.
- Проводите тесты длительной работы. Регулярно проверяйте, как приложение ведёт себя спустя часы и дни непрерывной эксплуатации. Профилирование памяти и своевременное освобождение ресурсов предотвращают замедления и вылеты.
- Минимизируйте критическую зависимость от внешних сервисов. Используйте graceful degradation, кеширование и очереди задач, чтобы приложение продолжало работать даже при временных сбоях API партнёров.
Приложение, которое выдерживает сбои, похоже на команду, которая их проектировала: оно предвидит больше, чем видит пользователь, и всегда знает, что делать дальше.




